
Introducción
¿Qué es NoSQL?
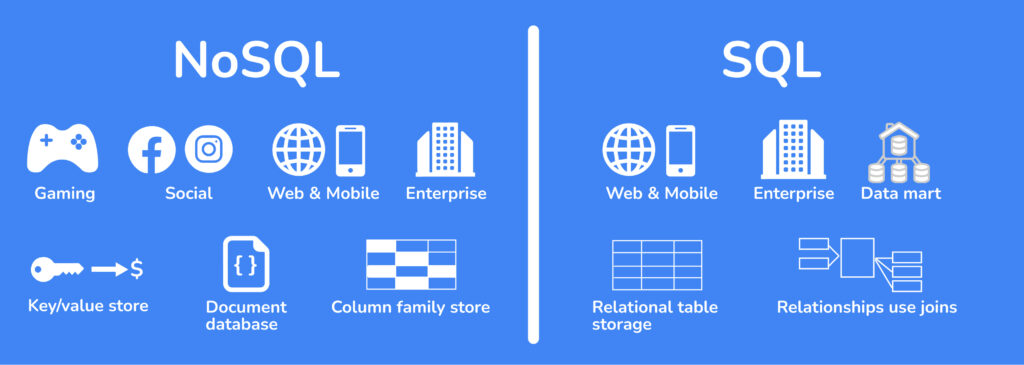
NoSQL (Not Only SQL) es un término que se utiliza para describir un conjunto de sistemas de gestión de bases de datos que utilizan modelos de datos no relacionales, en contraposición a los sistemas de gestión de bases de datos relacionales (RDBMS) tradicionales.
Los sistemas NoSQL están diseñados para manejar grandes cantidades de datos no estructurados o semiestructurados de manera eficiente y escalable.
A diferencia de las bases de datos relacionales, que utilizan tablas con filas y columnas, los sistemas NoSQL utilizan diferentes modelos de datos, como bases de datos de documentos, de grafos, de llave-valor y de columnas.
Estos modelos de datos permiten una mayor flexibilidad y escalabilidad en la gestión de grandes cantidades de datos y en el soporte de cargas de trabajo distribuidas y en tiempo real.
Entre las ventajas de las bases de datos NoSQL se encuentran la alta disponibilidad, la escalabilidad horizontal, la facilidad de uso, la flexibilidad en el esquema de datos y la capacidad de manejar grandes volúmenes de datos. Sin embargo, también existen algunas desventajas, como la falta de estándares, la falta de soporte para algunas operaciones complejas, la dificultad para realizar consultas complejas y la necesidad de más experiencia técnica para manejar estas bases de datos en comparación con las bases de datos relacionales.
¿Por qué es importante?
NoSQL es importante por varias razones:
- Escalabilidad: Están diseñados para ser escalables, lo que significa que pueden manejar grandes cantidades de datos y tráfico sin degradar el rendimiento. Esto los hace ideales para aplicaciones web y móviles de alta demanda, donde se necesita una rápida escalabilidad.
- Flexibilidad en el modelo de datos: Proporcionan una mayor flexibilidad en el diseño de los datos en comparación con las bases de datos relacionales. Esto se debe a que los modelos de datos NoSQL no están basados en tablas y relaciones, lo que significa que se pueden agregar o modificar datos en cualquier momento sin necesidad de modificar el esquema de la base de datos.
- Velocidad: Están diseñados para ofrecer un alto rendimiento, lo que significa que pueden manejar grandes cantidades de datos de forma rápida y eficiente. Esto se logra mediante la eliminación de restricciones y la utilización de técnicas de optimización de consultas.
- Disponibilidad: Están diseñados para proporcionar alta disponibilidad y tolerancia a fallos. Esto se logra mediante la replicación de los datos en múltiples servidores, lo que significa que si uno de los servidores falla, los datos todavía estarán disponibles en otro servidor.
- Big Data: Con el aumento en la cantidad de datos que se generan diariamente, la gestión y el procesamiento de grandes volúmenes de datos se ha vuelto más crítico. Los sistemas NoSQL son ideales para manejar grandes cantidades de datos no estructurados y semi-estructurados que no se ajustan a un esquema de base de datos tradicional.
En resumen, NoSQL es importante porque ofrece una mayor escalabilidad, flexibilidad, velocidad, disponibilidad y es capaz de manejar grandes volúmenes de datos no estructurados. Todo esto hace que sea una herramienta esencial para cualquier empresa que necesite manejar grandes cantidades de datos en tiempo real y con un alto rendimiento.
¿Cuándo usar NoSQL?
NoSQL es una buena opción cuando se necesita manejar grandes cantidades de datos no estructurados o semi-estructurados, o cuando se requiere una alta escalabilidad, disponibilidad y rendimiento. Por ejemplo:
- Big Data: Cuando se manejan grandes volúmenes de datos, como en el caso de las redes sociales, los sistemas NoSQL son ideales para manejar este tipo de datos no estructurados.
- Carga de trabajo distribuida: Cuando se necesita manejar una carga de trabajo distribuida, como en el caso de las aplicaciones web y móviles de alta demanda, los sistemas NoSQL son capaces de escalar horizontalmente, lo que significa que se pueden agregar más servidores a medida que aumenta la demanda.
- Flexibilidad en el esquema de datos: Cuando se necesita una mayor flexibilidad en el diseño de los datos, como en el caso de las aplicaciones que requieren una evolución rápida, los sistemas NoSQL permiten agregar o modificar datos en cualquier momento sin necesidad de modificar el esquema de la base de datos.
- Alta disponibilidad y tolerancia a fallos: Cuando se necesita una alta disponibilidad y tolerancia a fallos, como en el caso de las aplicaciones críticas, los sistemas NoSQL proporcionan replicación de datos y una mayor resistencia a los fallos de hardware y software.
- Análisis en tiempo real: Cuando se necesita procesar grandes cantidades de datos en tiempo real, como en el caso de la detección de fraudes, los sistemas NoSQL son capaces de procesar grandes volúmenes de datos en tiempo real.
Historia y evolución de NoSQL
La historia y evolución de NoSQL comienza en el año 1998 con la creación de la base de datos open-source "mSQL", que fue el precursor de MySQL.
A pesar de que MySQL se convirtió en una base de datos muy popular, su enfoque en las relaciones entre tablas y la necesidad de esquemas rígidos limitaba su capacidad para manejar grandes volúmenes de datos no estructurados.
A mediados de la década de 2000, la web y las aplicaciones móviles comenzaron a generar grandes volúmenes de datos no estructurados, lo que llevó a la necesidad de bases de datos que pudieran manejar este tipo de datos. En 2007, Google presentó un artículo sobre su sistema de base de datos distribuida "Bigtable", que se basaba en un modelo de datos de columnas y filas en lugar de tablas y relaciones. Bigtable fue la inspiración para muchas de las primeras bases de datos NoSQL.
En 2009, el término "NoSQL" fue acuñado por Johan Oskarsson para describir una nueva generación de bases de datos que no utilizaban SQL como lenguaje de consulta y que se basaban en modelos de datos no relacionales. Ese mismo año, MongoDB lanzó su primera versión y se convirtió en uno de los sistemas NoSQL más populares.
Desde entonces, se han creado muchos otros sistemas NoSQL, incluyendo Cassandra, Couchbase, HBase, Redis, y muchos más. A medida que la tecnología ha evolucionado, también lo han hecho los sistemas NoSQL, con características como la escalabilidad automática, la integración con tecnologías en la nube, y la capacidad de procesamiento en tiempo real.
En resumen, la historia y evolución de NoSQL se remonta a la necesidad de manejar grandes volúmenes de datos no estructurados que no podían ser gestionados de manera eficiente por las bases de datos relacionales tradicionales. La innovación de modelos de datos no relacionales, la flexibilidad, escalabilidad y velocidad han impulsado su crecimiento y popularidad en el mercado.
Ventajas y desventajas de NoSQL
Las bases de datos NoSQL tienen ventajas y desventajas en comparación con las bases de datos relacionales tradicionales.
Ventajas:
- Escalabilidad horizontal: Están diseñadas para escalar horizontalmente, lo que significa que se pueden agregar más servidores para aumentar la capacidad de almacenamiento y procesamiento a medida que aumenta la demanda.
- Flexibilidad de esquema: No tienen esquemas fijos, lo que significa que pueden manejar diferentes tipos de datos sin tener que ajustar un esquema de tabla existente.
- Rendimiento: Son capaces de procesar grandes cantidades de datos con alta velocidad y eficiencia.
- Alta disponibilidad y tolerancia a fallos: Suelen estar diseñadas para proporcionar alta disponibilidad y tolerancia a fallos, lo que significa que pueden continuar funcionando incluso si un servidor o nodo falla.
- Costo: Suelen ser menos costosas que las bases de datos relacionales tradicionales, especialmente para grandes volúmenes de datos.
Desventajas:
- Falta de estandarización: Al ser un conjunto diverso de tecnologías, carecen de una estandarización clara, lo que puede dificultar la interoperabilidad y la migración de datos entre sistemas.
- Menos madurez: Algunos sistemas NoSQL aún no tienen la madurez de las bases de datos relacionales tradicionales, lo que puede significar una menor estabilidad y soporte.
- Menos herramientas y habilidades disponibles: Tienen menos herramientas y habilidades disponibles en comparación con las bases de datos relacionales, lo que puede dificultar su implementación y mantenimiento.
- Limitaciones en la capacidad de consulta: No tienen una funcionalidad de consulta tan avanzada como las bases de datos relacionales, lo que puede dificultar la recuperación y el análisis de datos.
En resumen, las bases de datos NoSQL son una opción atractiva para manejar grandes volúmenes de datos no estructurados, pero también presentan algunas desventajas como la falta de estandarización y la limitación en la capacidad de consulta. Cada proyecto y caso de uso debe evaluarse cuidadosamente para determinar si NoSQL es la opción correcta.
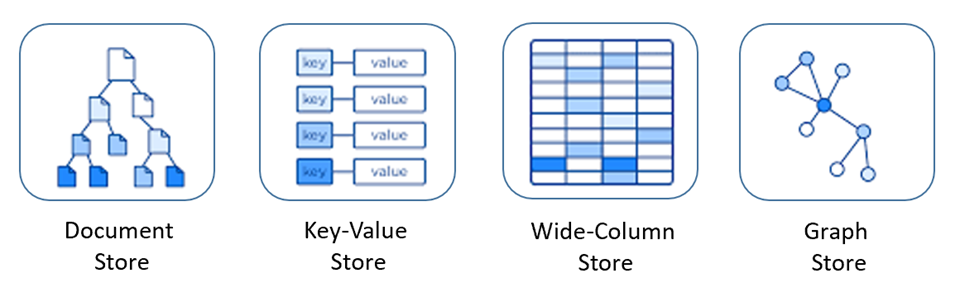
Bases de datos NoSQL
Existen diferentes tipos de bases de datos NoSQL, cada uno con características y enfoques específicos para manejar diferentes tipos de datos y problemas de escalabilidad.
A continuación, te presento algunos de los tipos de bases de datos NoSQL más comunes:
- Bases de datos de llave-valor: Almacenan datos como pares de llave-valor, donde la llave es un identificador único para el valor asociado. Este tipo de bases de datos es útil para almacenar y recuperar datos simples y muy rápidos. Ejemplo de estas bases de datos son: Redis, Riak, Amazon DynamoDB, etc.
- Bases de datos de columnas: Almacenan datos en columnas, en lugar de filas como en las bases de datos relacionales tradicionales. Este enfoque permite la escalabilidad horizontal y es especialmente útil para conjuntos de datos con muchos campos y poca variabilidad en los datos. Ejemplo de estas bases de datos son: Apache Cassandra, HBase, etc.
- Bases de datos de grafos: Almacenan datos como nodos y relaciones entre ellos, lo que los hace útiles para análisis de redes y relaciones complejas. Ejemplo de estas bases de datos son: Neo4j, OrientDB, ArangoDB, etc.
- Bases de datos de documentos: Almacenan datos en documentos JSON u otros formatos de documentos. Cada documento es una entidad completa que incluye todos los datos necesarios para esa entidad, lo que significa que los datos relacionados no necesitan estar divididos en diferentes tablas o colecciones. Ejemplo de estas bases de datos son: MongoDB, CouchDB, Apache Couchbase, etc.
Bases de llave-valor
Las bases de datos de llave-valor son un tipo de bases de datos NoSQL que almacenan y recuperan datos utilizando un modelo simple de pares de "llave-valor". Cada dato en la base de datos se guarda como un par, donde la "llave" es un identificador único que se utiliza para recuperar el "valor" asociado.
En este modelo, los datos se organizan en una estructura simple y plana, sin relaciones complejas ni jerarquías. Esto hace que las bases de datos de llave-valor sean muy eficientes en términos de rendimiento y escalabilidad. Al no tener esquemas fijos, permiten la flexibilidad en la forma en que se almacenan los datos.
Las operaciones básicas en una base de datos de llave-valor incluyen:
- Inserción: Se inserta un nuevo par de llave-valor en la base de datos. La llave debe ser única y el valor puede ser cualquier tipo de dato, como una cadena de texto, un número, un objeto JSON, entre otros.
- Actualización: Se actualiza el valor asociado a una llave existente en la base de datos.
- Eliminación: Se elimina un par de llave-valor de la base de datos.
- Recuperación: Se recupera el valor asociado a una llave específica.
Las bases de datos de llave-valor son especialmente útiles en casos de uso donde la velocidad y la simplicidad son prioritarias, como en aplicaciones de caché, sistemas de sesión, almacenamiento de metadatos, sistemas de colas, entre otros. Su diseño simple y su alto rendimiento las hacen ideales para escenarios que requieren un acceso rápido a los datos.
Algunos ejemplos de bases de datos de llave-valor populares son Redis, Riak y Amazon DynamoDB. Cada una tiene sus propias características y funcionalidades, pero todas comparten la simplicidad y eficiencia del modelo de llave-valor.
Redis
Redis es una base de datos de alto rendimiento y almacenamiento en caché en memoria que se utiliza ampliamente en aplicaciones web y sistemas distribuidos. Su nombre es una abreviatura de "REmote DIctionary Server" (Servidor de Diccionario Remoto), y se caracteriza por su capacidad para almacenar datos en una estructura de datos de llave-valor en memoria.
Principales características:
- Almacenamiento en memoria: almacena todos los datos en la memoria principal, lo que le permite ofrecer un acceso extremadamente rápido a los datos. Esto lo convierte en una opción ideal para aplicaciones donde la latencia es crítica.
- Modelos de datos versátiles: admite una variedad de estructuras de datos, como cadenas de texto, listas, conjuntos, hash, conjuntos ordenados y bitmaps. Esto permite una mayor flexibilidad en el almacenamiento y manipulación de datos según las necesidades específicas de la aplicación.
- Operaciones atómicas: proporciona operaciones atómicas en las estructuras de datos, lo que garantiza que una operación se ejecute en su totalidad sin intervención de otras operaciones concurrentes. Esto es útil para casos donde se requiere consistencia y seguridad en las operaciones.
- Persistencia opcional: Aunque almacena los datos en memoria, también proporciona opciones de persistencia en disco, lo que permite que los datos se mantengan incluso después de un reinicio del servidor. Esto se logra mediante la escritura de los datos en disco en forma de snapshots o mediante el uso de registros de transacciones.
- Capacidades avanzadas: ofrece una variedad de características avanzadas, como la capacidad de publicar y suscribir a canales de mensajes, realizar operaciones de bloqueo para garantizar la exclusión mutua, soporte para scripts Lua personalizados y la posibilidad de configurar clústeres para alta disponibilidad y escalabilidad.
Redis se utiliza ampliamente en aplicaciones que requieren una alta velocidad de acceso a datos, como almacenamiento en caché, gestión de sesiones de usuario, conteo de visitas, colas de mensajes, análisis en tiempo real y más. Además, es altamente extensible y cuenta con una comunidad activa que contribuye con módulos y herramientas adicionales.
Espero que esta introducción te haya dado una visión general de Redis y sus características principales. Para más información consulta los siguientes enlaces:
Bases orientadas a columnas
Las bases de datos de columnas, también conocidas como bases de datos orientadas a columnas, son un tipo de base de datos NoSQL que almacenan y organizan los datos en columnas en lugar de filas. A diferencia de las bases de datos relacionales tradicionales, donde los datos se almacenan en filas y se agrupan en tablas, las bases de datos de columnas almacenan cada columna de datos de manera contigua y se enfocan en recuperar y analizar selectivamente columnas específicas.
Principales características:
- Compresión y eficiencia de almacenamiento: al almacenar los datos de una columna juntos, pueden aplicar técnicas de compresión específicas de la columna, lo que puede reducir significativamente el espacio de almacenamiento requerido y mejorar la eficiencia de lectura y escritura.
- Acceso selectivo a columnas: las consultas pueden recuperar y analizar selectivamente columnas específicas en lugar de tener que leer todas las columnas en una fila. Esto permite un acceso más rápido a los datos y un menor uso de recursos.
- Alto rendimiento en análisis y agregaciones: están optimizadas para consultas analíticas y agregaciones en grandes conjuntos de datos. Al almacenar columnas juntas, pueden realizar operaciones de agregación, como SUM, COUNT y AVG, de manera más eficiente.
- Escalabilidad horizontal: son altamente escalables horizontalmente, lo que significa que se pueden agregar nuevos nodos y distribuir los datos en clústeres para manejar grandes volúmenes de datos y cargas de trabajo intensivas.
- Flexibilidad de esquema: al igual que otras bases de datos NoSQL, ofrecen flexibilidad en el esquema de datos, lo que permite agregar, eliminar o modificar columnas sin afectar el esquema global de la base de datos.
Algunos ejemplos populares de bases de datos de columnas son Apache Cassandra, Apache HBase y ScyllaDB. Estas bases de datos son ampliamente utilizadas en aplicaciones que manejan grandes volúmenes de datos y necesitan un rendimiento rápido en consultas analíticas y agregaciones.
En resumen, las bases de datos de columnas ofrecen un enfoque eficiente y optimizado para almacenar y recuperar datos, especialmente para aplicaciones que requieren análisis y agregaciones rápidas en grandes conjuntos de datos. Su diseño centrado en columnas, compresión eficiente y escalabilidad horizontal las hacen ideales para casos de uso donde la velocidad y el rendimiento son críticos.
Apache Cassandra
Apache Cassandra es una base de datos distribuida, altamente escalable y de alto rendimiento, diseñada para manejar grandes volúmenes de datos y proporcionar alta disponibilidad sin puntos únicos de fallo. Fue desarrollada originalmente por Facebook y luego se convirtió en un proyecto de código abierto de la Apache Software Foundation.
Principales características:
- Escalabilidad horizontal: está diseñada para escalar horizontalmente de manera transparente al agregar nuevos nodos al clúster. Esto permite manejar grandes volúmenes de datos y cargas de trabajo intensivas.
- Modelo de datos sin esquema: es una base de datos NoSQL que utiliza un modelo de datos sin esquema fijo. Esto significa que no requiere un esquema predeterminado y puede almacenar diferentes estructuras de datos en diferentes filas dentro de una misma tabla.
- Alta disponibilidad y tolerancia a fallos: está diseñada para ser altamente disponible y tolerante a fallos. Utiliza una arquitectura distribuida en la que los datos se replican automáticamente en múltiples nodos, lo que permite que el sistema continúe funcionando incluso en caso de fallas de nodos individuales.
- Rendimiento rápido en escrituras y lecturas: está optimizada para proporcionar un alto rendimiento en operaciones de escritura y lectura. Utiliza una estructura de registro de escritura optimizada para evitar problemas de bloqueo y garantizar un rendimiento rápido en escrituras.
- Consultas flexibles: admite consultas flexibles utilizando su propio lenguaje de consulta llamado CQL (Cassandra Query Language) que es similar a SQL y permite realizar consultas ricas en datos utilizando índices y filtros.
- Soporte para replicación multi-región: proporciona capacidades de replicación multi-región, lo que permite distribuir los datos en diferentes ubicaciones geográficas. Esto es útil para garantizar la baja latencia de las operaciones y cumplir con los requisitos de cumplimiento normativo.
- Integración con herramientas de la familia Apache: se integra de manera nativa con herramientas populares de análisis de datos como Apache Spark y Apache Hadoop, lo que permite realizar análisis y consultas complejas en grandes conjuntos de datos.
Apache Cassandra se utiliza en una amplia gama de aplicaciones, incluyendo redes sociales, aplicaciones de IoT, sistemas de seguimiento y análisis de registros, aplicaciones de comercio electrónico y mucho más. Su escalabilidad, rendimiento y capacidad de manejar grandes volúmenes de datos hacen que sea una opción popular para casos de uso que requieren un alto rendimiento y disponibilidad.
Espero que esta introducción te haya dado una visión general de Apache Cassandra y sus características principales. Para más información consulta los siguientes enlaces:
Bases orientadas a grafos
Las bases de datos de grafos son un tipo de base de datos diseñada específicamente para almacenar y consultar datos en forma de grafos. En un grafo, los datos se representan como nodos (también conocidos como vértices) y las relaciones entre los nodos se representan como aristas (también conocidas como bordes). Esta estructura permite modelar y analizar relaciones complejas entre los datos de manera eficiente.
Principales características:
- Modelo de datos basado en grafos: que es ideal para representar y trabajar con datos que tienen relaciones complejas. Cada nodo representa una entidad y las aristas representan las relaciones entre esas entidades.
- Relaciones y propiedades: Además de las aristas que conectan los nodos, los nodos y las aristas también pueden tener propiedades asociadas. Estas propiedades pueden representar información adicional sobre los nodos y las relaciones.
- Consultas y análisis de relaciones: están optimizadas para ello y pueden realizar consultas complejas que siguen los caminos y patrones de las relaciones entre los nodos de manera eficiente.
- Flexibilidad y escalabilidad: son altamente flexibles y escalables. Pueden manejar fácilmente conjuntos de datos grandes y crecer a medida que aumenta el tamaño y la complejidad de los datos.
- Descubrimiento de patrones y recomendaciones: son especialmente útiles para descubrir patrones, identificar conexiones ocultas y realizar recomendaciones basadas en las relaciones entre los datos. Son ampliamente utilizadas en aplicaciones de recomendación, análisis de redes sociales y detección de fraudes, entre otros casos de uso.
- Integración con lenguaje de consulta específico: proporcionan un lenguaje de consulta específico para realizar consultas y análisis de grafos. Por ejemplo, Cypher para Neo4j y Gremlin para Apache TinkerPop.
Algunos ejemplos populares de bases de datos de grafos incluyen Neo4j, Amazon Neptune, JanusGraph, Apache TinkerPop y ArangoDB. Cada una de estas bases de datos tiene características y enfoques ligeramente diferentes, pero todas comparten el enfoque de modelado de datos basado en grafos y la capacidad de trabajar con relaciones complejas de manera eficiente.
En resumen, las bases de datos de grafos son una poderosa herramienta para almacenar, consultar y analizar datos con relaciones complejas. Su enfoque en el modelado de datos basado en grafos permite descubrir información valiosa y patrones ocultos en los datos.
Neo4j
Neo4j es una base de datos de grafos líder en el mercado, diseñada específicamente para almacenar, consultar y analizar datos en forma de grafos. Es altamente escalable, flexible y optimizada para trabajar con relaciones complejas entre los datos. Neo4j utiliza el lenguaje de consulta Cypher, que es un lenguaje específico de dominio para consultas de grafos.
Principales características:
- Modelo de datos basado en grafos: utiliza un modelo de datos basado en grafos, donde los datos se representan como nodos y relaciones entre los nodos. Los nodos representan entidades y las relaciones representan las conexiones entre esas entidades.
- Consultas y análisis de grafos: permite realizar consultas y análisis sofisticados de grafos utilizando su lenguaje de consulta Cypher, que es intuitivo y fácil de usar que permite expresar patrones y relaciones complejas en los datos.
- Alto rendimiento y escalabilidad: está diseñada para ofrecer un alto rendimiento y escalabilidad. Puede manejar grandes volúmenes de datos y crecer horizontalmente agregando más nodos al clúster.
- Flexibilidad en el esquema: A diferencia de las bases de datos relacionales, no requiere un esquema fijo y rígido. Permite la flexibilidad en la definición de propiedades y relaciones en tiempo de ejecución, lo que facilita la adaptación a cambios en los datos.
- Indexación y búsqueda eficiente: proporciona capacidades de indexación eficientes para acelerar las búsquedas y consultas en los datos de grafos. Esto permite un acceso rápido a los nodos y relaciones relevantes en grandes conjuntos de datos.
Neo4j es ampliamente utilizado en una variedad de aplicaciones y casos de uso, incluyendo análisis de redes sociales, recomendaciones personalizadas, detección de fraudes, gestión de identidad y acceso, gestión de conocimientos y muchas más.
Neo4j ofrece una gama de ediciones, incluyendo una edición gratuita llamada Neo4j Community Edition y una edición comercial llamada Neo4j Enterprise Edition, que ofrece características adicionales, escalabilidad empresarial y soporte técnico.
Neo4j se integra bien con varios lenguajes de programación y marcos de desarrollo, y cuenta con una comunidad activa que proporciona recursos, documentación y ejemplos para ayudar a los desarrolladores a aprovechar al máximo la base de datos.
Espero que esta introducción te haya dado una visión general de Neo4j y sus características principales. Para más información consulta los siguientes enlaces:
Bases orientadas a documentos
Las bases de datos de documentos son un tipo de base de datos NoSQL que están diseñadas para almacenar, recuperar y gestionar datos en forma de documentos. Un documento es una unidad de datos autocontenido que puede contener información estructurada en un formato flexible, como JSON o BSON. Cada documento puede tener una estructura diferente y no se requiere un esquema fijo y predefinido.
Principales características:
- Modelo de datos basado en documentos: en lugar de utilizar una estructura de tablas y filas como en las bases de datos relacionales, las bases de datos documentales almacenan los datos en documentos individuales. Cada documento puede contener información compleja y estructurada, como campos anidados y matrices.
- Flexibilidad en el esquema: ofrecen flexibilidad en el esquema, lo que significa que los documentos individuales no necesitan seguir un esquema fijo. Cada documento puede tener su propia estructura y no se requiere una estructura uniforme para todos los documentos en la base de datos.
- Consultas y búsquedas eficientes: proporcionan una amplia gama de operaciones de consulta y búsqueda para acceder a los datos almacenados en los documentos. Pueden realizar consultas flexibles utilizando índices y proporcionar un alto rendimiento en búsquedas.
- Escalabilidad horizontal: están diseñadas para escalar horizontalmente al agregar nuevos nodos a un clúster. Esto permite manejar grandes volúmenes de datos y cargas de trabajo intensivas.
- Replicación y alta disponibilidad: Para garantizar la disponibilidad de datos, muchas bases de datos de documentos admiten la replicación de datos en múltiples nodos, lo que permite una mayor disponibilidad y tolerancia a fallos.
- Integración con lenguajes de programación y marcos de desarrollo: suelen proporcionar bibliotecas y controladores para una fácil integración con diferentes lenguajes de programación y marcos de desarrollo. Esto facilita el desarrollo de aplicaciones utilizando la base de datos de documentos elegida.
Algunos ejemplos populares de bases de datos de documentos son MongoDB, Couchbase, Apache CouchDB y Amazon DocumentDB. Estas bases de datos son ampliamente utilizadas en aplicaciones web, aplicaciones móviles, sistemas de gestión de contenidos (CMS), sistemas de gestión de usuarios y muchas otras aplicaciones que requieren flexibilidad y escalabilidad en el manejo de datos no estructurados o semi-estructurados.
MongoDB
MongoDB es una base de datos de documentos NoSQL, de código abierto y orientada a documentos más populares y ampliamente utilizadas en la actualidad. Se caracteriza por su flexibilidad, escalabilidad y rendimiento.
Principales características:
- Modelo de datos basado en documentos: almacena los datos en documentos BSON (Binary JSON), que son documentos JSON extendidos con tipos de datos adicionales. Los documentos BSON se organizan en colecciones, que son similares a las tablas en las bases de datos relacionales.
- Flexibilidad en el esquema: ofrece un esquema flexible, lo que significa que cada documento en una colección puede tener una estructura diferente. No se requiere un esquema fijo y predefinido, lo que permite una fácil adaptación a los cambios en los datos.
- Alta escalabilidad: es altamente escalable y permite escalar horizontalmente mediante la distribución de datos en múltiples servidores. Esto permite manejar grandes volúmenes de datos y cargas de trabajo intensivas.
- Consultas y búsquedas eficientes: proporciona un potente lenguaje de consulta para realizar consultas y búsquedas flexibles en los datos almacenados. Admite una amplia gama de operaciones de consulta, incluyendo filtrado, proyección, agregación y búsqueda basada en índices.
- Alta disponibilidad y replicación: ofrece opciones de replicación para garantizar la disponibilidad de los datos y la tolerancia a fallos. Los datos se pueden replicar en múltiples nodos, lo que permite una mayor disponibilidad y permite la recuperación ante fallos.
- Escalabilidad geográfica: cuenta con funcionalidades para la distribución de datos a través de múltiples regiones geográficas. Esto permite la creación de clústeres distribuidos en diferentes ubicaciones geográficas para garantizar un acceso rápido a los datos en diferentes partes del mundo.
- Integración con lenguajes y marcos de desarrollo: cuenta con controladores y bibliotecas para una amplia variedad de lenguajes de programación y marcos de desarrollo. Esto facilita la integración con diferentes tecnologías y el desarrollo de aplicaciones.
MongoDB es ampliamente utilizado en aplicaciones web, aplicaciones móviles, sistemas de análisis de datos, sistemas de gestión de contenidos (CMS), sistemas de gestión de usuarios y muchos otros casos de uso que requieren flexibilidad y escalabilidad en el manejo de datos.
MongoDB ofrece tanto una versión de comunidad gratuita como una versión comercial llamada MongoDB Enterprise, que proporciona características adicionales, escalabilidad empresarial y soporte técnico.
Espero que esta introducción te haya dado una visión general de MongoDB y sus características principales. Para más información consulta los siguientes enlaces:
Aprende más
Si estás interesado en aprender más sobre bases de datos, no te pierdas mis cursos totalmente gratuitos en mi canal de YouTube.
¡¡¡Accede ya!!!
🌱 estás en mi jardín digital 🌱
🦊🐺🐸🐧🪲🐉🦍🐅🐥🌟🪶